BANA6043: ANOVA in SAS
Matt Risley
Week 3 Lecture Series
1 Introduction
Using the morley and warpbreaks datasets, this lecture demonstrates how to conduct hypothesis testing in SAS through PROC ANOVA.
The primary difference between t-tests and ANOVA is the number of groups you can analyze. t-tests are limited to a comparison between two groups while ANOVA can compare multiple groups as well as interactions between groups. ANOVA uses the F distribution and is sometimes referred to as an F-test.
2 ANOVA hypotheses
For a t-test you have a null that compares two means:
H0: μ1 = μ2
For ANOVA, you compare more than two means:
H0: μ1 = μ2 = μ3 = … = μn
where n = total number of groups
The ANOVA alternative hypothesis is usually not written in mathematical notation:
H1: at least one mean is different from the rest
The following outcomes would result in a rejection of the null in favor of the alternative:
- one mean is different from the rest
- two means are different from the rest, but they are not different from one another
- two means are different from the rest, and they are different from on another
- (all other possible combinations)
- all means are different from one another
3 ANOVA on morley dataset
As a refresher, the morley dataset contains measures of the speed of light from 5 experiments, each with 20 runs:
proc print data=mrrlib.morley(obs=25 drop=VAR1); run;
3.1 the hypothesis
We will test the hypothesis that all the means from the five experiments are the same. From a practical perspective, we could reword this as:
we are testing the hypothesis that the experimental design influenced the values of the speed of light
Formally, the null hypothesis is:
H0: μexpt1 = μexpt2 = μexpt3 = μexpt4 = μexpt5
And the alternative:
H1: at least one mean is different from the rest
3.2 the procedure
ods graphics on;
proc anova data=mrrlib.morley;
class expt;
model speed = expt;
label expt = "Experiment #";
run;
ods graphics off;- the
modelstatement specifies your target variable of interest as well as one or more effects you with to test- we are testing whether experiment (our main effect) influences the measured speed of light
- we are testing whether experiment (our main effect) influences the measured speed of light
- any effect variables specified on the right hand side of the model must be present in the `
classstatement labelstatement will convert instances of “expt” in the output to “Experiment #”
3.3 output interpretation
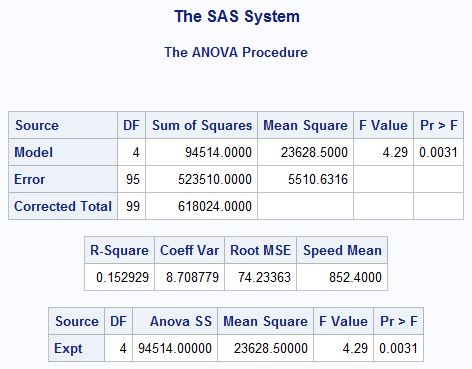
- the first box shows details of the model, some of which are repeated below it
- DF (degrees of freedom) is used to determine the F statistic
- p-value is the statistical significance of the model
- R-square tells you the amount of variance in speed that is explained by expt
- 15% explained
- 15% explained
- Root MSE (Mean Squared Error) tells you the average error when using expt to predict speed
- significant p-value indicates that expt has a significant effect on speed because at least one mean speed from the experiments is different from the others
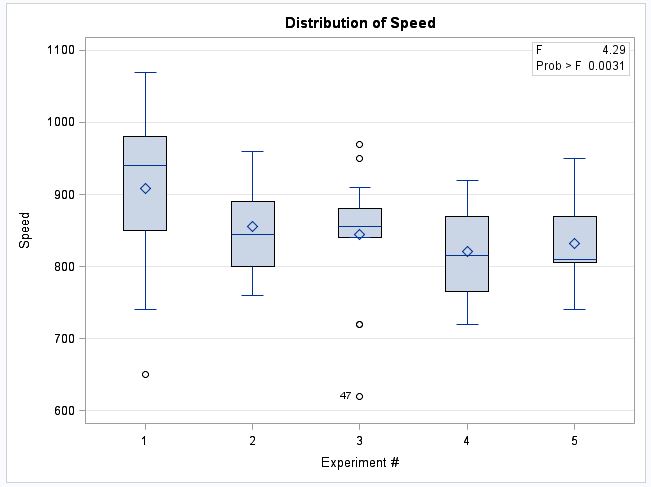
- boxplot provides a visual display of the distributions of speed for each experiment
4 ANOVA on warpbreaks dataset
As a refresher, the warpbreak dataset contains data on the number of breaks in yarn per loom for 54 runs. Half the runs use Wool Type A and the other half use Wool Type B. For each wool type, three degrees of tension are applied–low, medium, and high.
proc print data=mrrlib.warpbreaks(obs=10 drop=VAR1); run;
4.1 simple effect models
We will test the hypothesis that the number of breaks are the same for each wool type. We will also test the hypothesis that the number of breaks are the same for each tension type. We will test them independently.
Formally, the null hypotheses are:
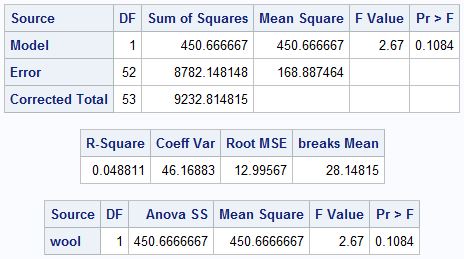
H0: μA = μB
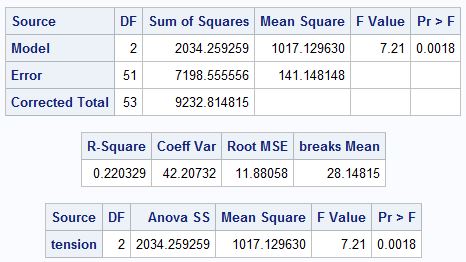
H0: μL = μM = μH
And the alternatives for both null hypotheses:
H1: at least one mean is different from the rest
4.1.1 the procedure
ods graphics on;
proc anova data=mrrlib.warpbreaks;
class tension;
model breaks = tension;
run;
proc anova data=mrrlib.warpbreaks;
class wool;
model breaks = wool;
run;
proc ttest data=mrrlib.warpbreaks plots=none;
class wool;
var breaks;
run;
ods graphics off;tension
wool
4.1.2 conclusions
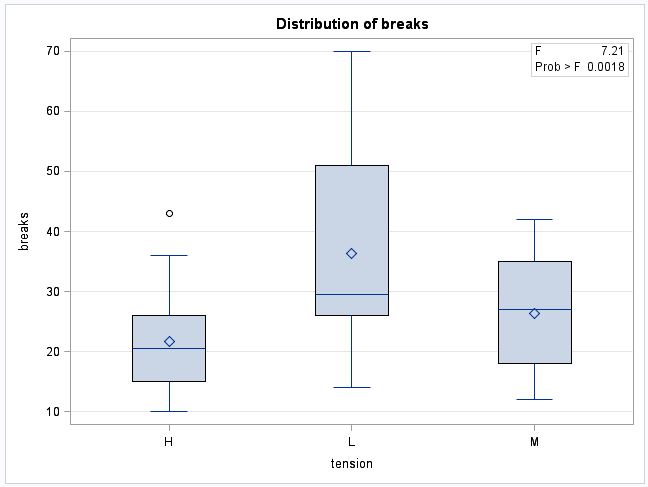
- tension has a significant effect on the number of breaks
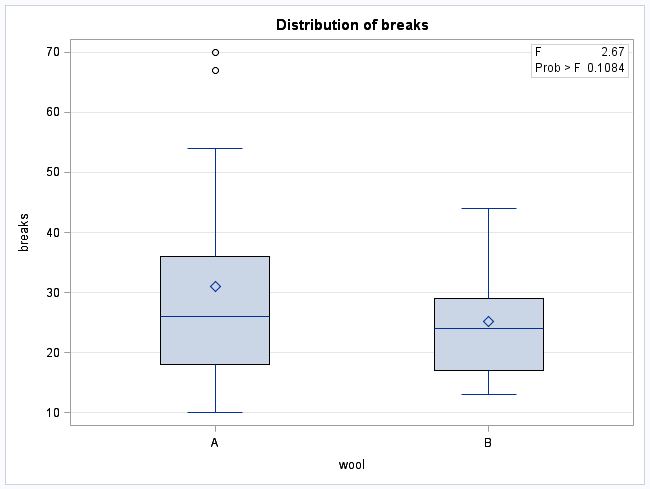
- wool does not have a significant effect on the number of breaks at α = 0.10
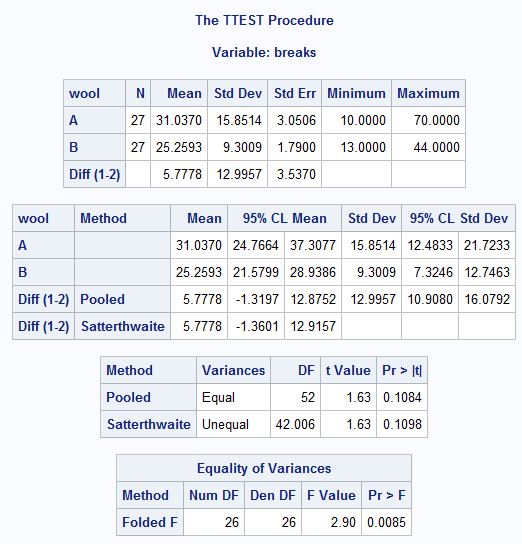
an F-test of two means is equivalent to a t-test
t-test on wool
4.2 two-factor main effects model
We want to test whether wool and tension have a significant effect on the number of breaks. This is a two-factor main effects model.
In a two-factor (or multi-factor) main effects model, you are testing the effects of two (or more) variables when considered together.
Let’s consider the difference for wool type in the simple effects model and the two-factor main effects model:
simple effects model: wool type affects the number of breaks
This simple effects model does not control for any other variable.
two-factor main effects model: wool type affects the number of breaks after controlling for tension
The two-factor main effects model tests the influence of wool on breaks at the average number of breaks for each tension type. This is the ceteris paribus (“all else held equal”) assumption. We can rephrase the hypothesis with this language:
two-factor main effects model: tension type held equal, wool type affects the number of breaks
NOTE: the “all else held equal” assumption also applies to the interpretation of regression coefficients.
4.2.1 visualizing the two-factor model
Visualizing the grouping under the simple effects and two-factor model makes the difference more concrete.
4.2.1.1 wool boxplot
Let’s start for the testing of main effect for wool:
ods graphics on;
proc sgplot data=mrrlib.warpbreaks;
vbox breaks / group=wool
groupdisplay=clustered;
title "wool only: simple effect";
run;
proc sgplot data=mrrlib.warpbreaks;
vbox breaks / category=tension
group=wool
groupdisplay=clustered;
title "wool & tension: wool main effect";
run;
ods graphics off;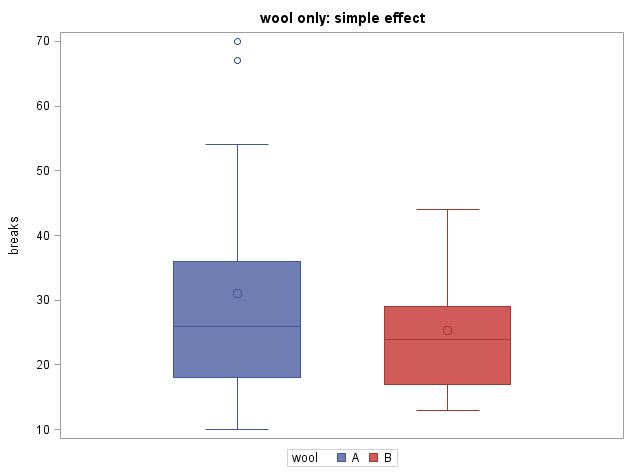
in the simple effects model, we test the difference in the mean # of breaks for wool type A (blue) and B (red)
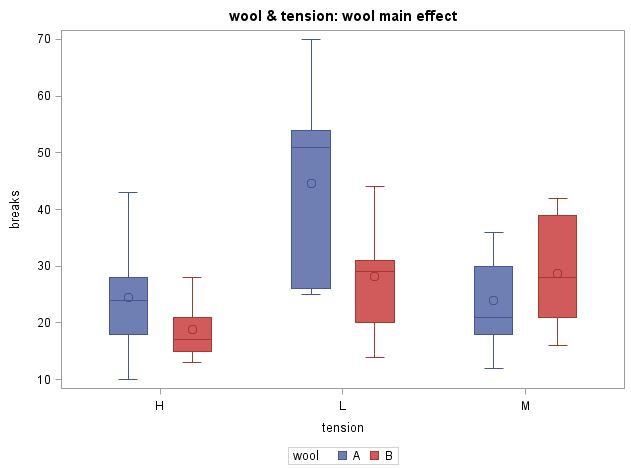
in the simple effects model, we test the difference in the mean # of breaks for wool type A (blue) and B (red) at each level of tension
4.2.1.2 tension boxplot
Now for the testing of main effect for tension:
ods graphics on;
proc sgplot data=mrrlib.warpbreaks;
vbox breaks / group=tension
groupdisplay=clustered;
title "tension only: simple effect";
run;
proc sgplot data=mrrlib.warpbreaks;
vbox breaks / category=wool
group=tension
groupdisplay=clustered;
title "wool & tension: tension main effect";
run;
ods graphics off;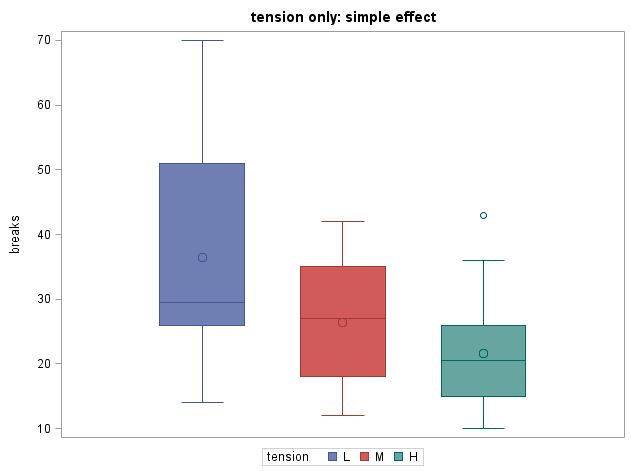
in the simple effects model, we test the difference in the mean # of breaks for tension L (blue), M (red), and H (green)
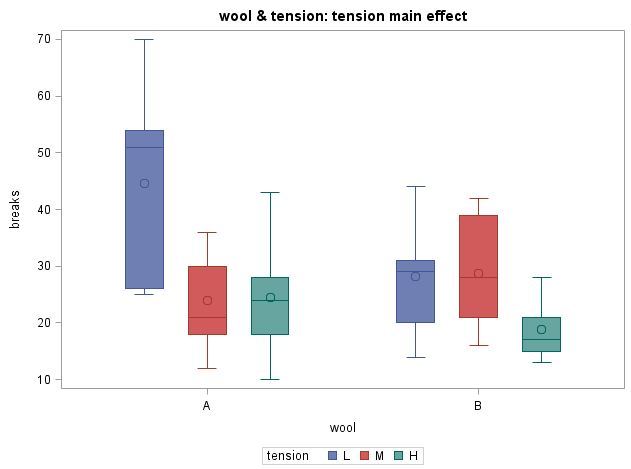
in the simple effects model, we test the difference in the mean # of breaks for tension L (blue), M (red), and H (green) for each wool type
4.2.2 the procedure
proc anova data=mrrlib.warpbreaks;
class tension wool;
model breaks = tension wool;
run;In order to test the two-factor model, we include both variables in the class statement and on the right hand of the model.
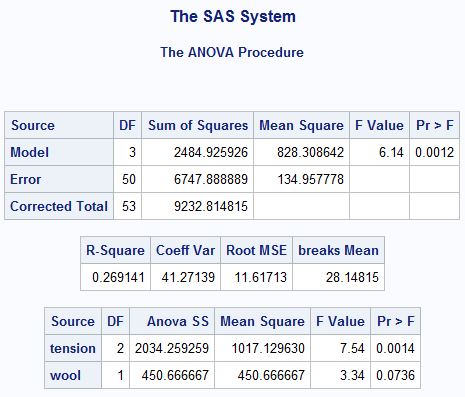
- the first box gives us a summary for the two-factor model
- we can see the model is significant at the 0.01 level with a p-value of 0.0012
- we can see the model is significant at the 0.01 level with a p-value of 0.0012
- the second box gives us additional information about the model
- wool and tension together explain 26.9% of the variation in the number of breaks
- on average, the model’s prediction error is +/- 11 breaks.
- the third box gives the results for tension and wool
- in comparison to the simple effects model, we now see wool is significant at the 0.10 level
4.3 two-factor main effects model with interaction
It is reasonable to think that breaks are influenced by the interaction of wool type and tension. The wool types could have different properties that influence the number of breaks at various tensions. For example, low tension could result in the fewest breaks for wool type A, but it could result in the highest breaks for wool type B.
proc anova data=mrrlib.warpbreaks;
class tension wool;
model breaks = tension|wool;
run;To test the levels as well as the interaction between two variables, you can use the | symbol between the variables. Alternative, you could write the model statement as:
model breaks = tension wool tension*wool;
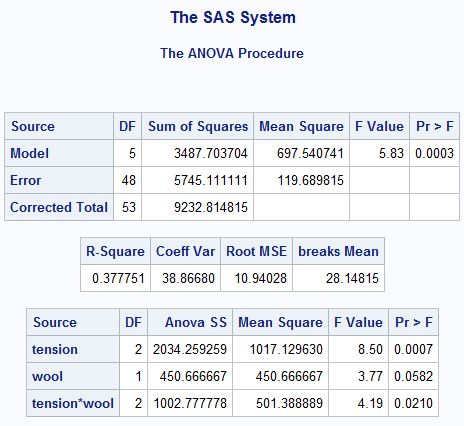
The results show us that:
- the interaction effect is significant
- the main effect of wool is nearly significant at the 0.05 level
- an additional 10% of variance is explained with the inclusion of the interaction term
Beware: R-square is a POOR measure of model comparison because:
R-square always increases with the inclusion of another factor
R-square does not penalize overfit
However, an increase in R-square of 0.10 from a single factor is a fairly significant amount of addition variance explained by a single factor.